
Evaluator-Optimizer Pattern
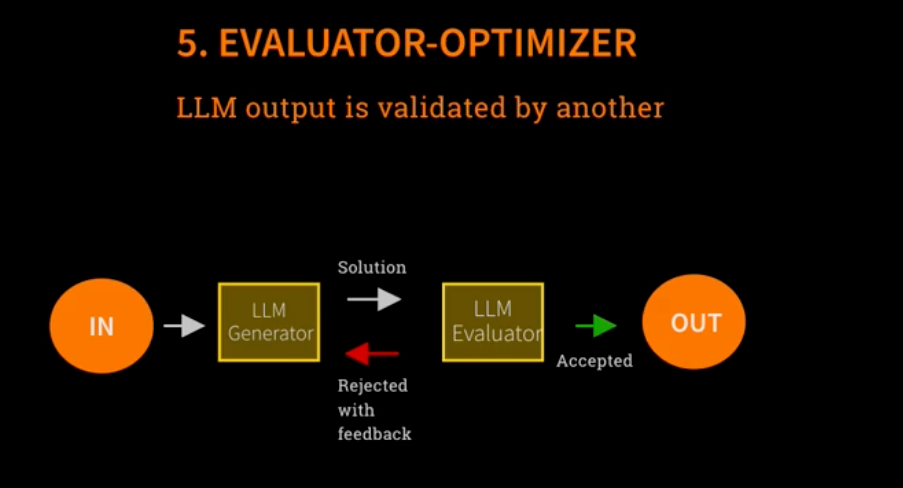
The evaluator-optimizer pattern represents a sophisticated quality assurance approach in LLM systems where two specialized agents work in tandem to improve output reliability through iterative feedback loops. A generator LLM produces initial solutions while a dedicated evaluator LLM acts as a critic, equipped with additional context and validation criteria to assess the generator's work. When the evaluator rejects output, it provides specific feedback that enables the generator to produce improved iterations, creating a self-correcting system. This pattern addresses one of the most critical challenges in production AI systems—ensuring consistent quality and accuracy—by institutionalizing a review process that mirrors human collaborative workflows like peer review, editorial processes, and quality assurance practices. The pattern's effectiveness lies in its ability to leverage specialized roles, iterative improvement, and explicit feedback mechanisms to achieve higher confidence in AI-generated outputs than single-agent approaches.
Key Terms & Definitions
Evaluator-Optimizer Pattern: A two-agent workflow where a generator creates solutions and an evaluator validates them, creating feedback loops for iterative improvement.
Generator LLM: The primary agent responsible for producing initial solutions, responses, or content based on the given task or prompt.
Evaluator/Validation Agent: A secondary LLM specialized in assessing the quality, accuracy, and appropriateness of the generator's output using specific criteria and additional context.
Feedback Loop: The iterative cycle where rejected outputs are returned to the generator with specific reasons for rejection, enabling continuous improvement.
Validation Context: Additional information, criteria, or domain knowledge provided to the evaluator to enhance its assessment capabilities beyond what the generator receives.
Accept/Reject Decision: The binary evaluation outcome where the evaluator either approves the output for final use or returns it for revision.
Iterative Refinement: The process of repeatedly improving outputs through multiple generator-evaluator cycles until acceptable quality is achieved.
Quality Gate: A checkpoint in the workflow where outputs must meet specific standards before proceeding to the next stage or final delivery.
Self-Correction Mechanism: The system's ability to identify and fix its own errors through the evaluator's feedback without external intervention.
Production Confidence: The increased reliability and trust in AI system outputs achieved through systematic validation processes.
Convergence Criteria: The conditions that determine when the iterative improvement process should terminate (e.g., maximum iterations, quality threshold met).
Important People & Events
Key Figures & Organizations
Anthropic: AI safety company that coined the term "evaluator-optimizer" and has extensively documented and promoted this pattern as a fundamental workflow for reliable AI systems.
Ian Goodfellow: Creator of Generative Adversarial Networks (GANs) in 2014, which established the theoretical foundation for adversarial training and generator-critic architectures.
OpenAI: Organization that has implemented various forms of evaluator-optimizer patterns in their production systems, particularly in content moderation and quality assurance.
Timeline of Related Developments
1950s-1960s: Early software testing methodologies establish the principle of separation between code generation and validation processes.
1990s-2000s: Peer review systems in academia formalize the concept of expert evaluation and iterative improvement of scholarly work.
2000s-2010s: Software development adopts automated testing and continuous integration, institutionalizing validation loops in development workflows.
2014: Introduction of Generative Adversarial Networks (GANs) by Ian Goodfellow, establishing adversarial training as a powerful ML paradigm.
2017-2020: Development of Reinforcement Learning from Human Feedback (RLHF) techniques, showing the effectiveness of feedback-based improvement in language models.
2020-2022: Large language models demonstrate both impressive capabilities and concerning failure modes, highlighting the need for systematic validation approaches.
2022-2023: Companies like Anthropic and OpenAI begin systematically implementing and documenting evaluator-optimizer patterns in production systems.
2023-Present: Evaluator-optimizer becomes a standard pattern in enterprise AI deployments, particularly for high-stakes applications requiring reliability.
Architecture Components
The Generator Agent
- Primary Function: Creative and generative problem-solving
- Optimization Target: Producing comprehensive, relevant solutions
- Input Sources: User prompts, task specifications, domain context
- Output Characteristics: First-draft solutions requiring validation
- Learning Mechanism: Incorporates feedback from evaluator to improve subsequent generations
The Evaluator Agent
- Primary Function: Critical assessment and quality control
- Optimization Target: Accurate identification of flaws and improvement opportunities
- Input Sources: Generator outputs, validation criteria, additional context, domain expertise
- Output Characteristics: Accept/reject decisions with detailed justifications
- Specialized Knowledge: Often equipped with evaluation rubrics, checklists, or domain-specific validation rules
The Feedback Loop
- Information Flow: Bidirectional communication between generator and evaluator
- Iteration Control: Manages the cycle count and termination conditions
- Quality Metrics: Tracks improvement over iterations
- Convergence Management: Determines when acceptable quality is achieved
Process Flow
- Initial Generation: Generator produces first solution attempt
- Evaluation Phase: Evaluator assesses output against criteria
- Decision Point: Accept (proceed) or Reject (iterate)
- Feedback Delivery: If rejected, specific reasons provided to generator
- Regeneration: Generator creates improved version incorporating feedback
- Repeat Cycle: Continue until acceptance or maximum iterations reached
- Final Output: Deliver validated solution with confidence metrics
Advantages & Benefits
Quality Improvements
- Error Detection: Systematic identification of factual errors, logical inconsistencies, and quality issues
- Iterative Refinement: Multiple improvement cycles lead to higher-quality outputs
- Consistency: Standardized evaluation criteria ensure uniform quality across different tasks
Reliability & Trust
- Production Confidence: Higher assurance in system outputs for critical applications
- Failure Mode Reduction: Catches potential issues before they reach end users
- Audit Trail: Clear record of evaluation decisions and improvement iterations
Specialization Benefits
- Role Optimization: Each agent can be optimized for its specific function (generation vs. evaluation)
- Context Enrichment: Evaluators can access specialized knowledge not available to generators
- Bias Mitigation: Different perspectives from generator and evaluator can reduce systematic biases
Challenges & Limitations
Computational Costs
- Resource Overhead: Multiple LLM calls per task increase computational requirements
- Iteration Costs: Each revision cycle doubles or triples the computational expense
- Scalability Concerns: Cost scaling becomes prohibitive for high-volume applications
Design Complexity
- Evaluation Criteria: Defining effective validation rules requires domain expertise
- Evaluator Bias: Risk of systematic biases in the evaluation process
- Infinite Loops: Potential for non-convergent cycles where no solution is ever accepted
Performance Trade-offs
- Latency Increase: Multiple iterations significantly increase response time
- Diminishing Returns: Later iterations may provide minimal quality improvements
- Over-optimization: Risk of producing technically correct but less creative or natural outputs
Comparison with Related Patterns
vs. Single-Agent Systems
- Quality: Higher accuracy through validation but at computational cost
- Speed: Slower due to multiple evaluation cycles
- Complexity: More complex to design and debug
vs. Human-in-the-Loop Systems
- Scalability: Fully automated vs. requiring human reviewers
- Cost: Higher upfront computational cost vs. ongoing human labor cost
- Speed: Faster than human review but slower than single-agent
vs. Ensemble Methods
- Approach: Sequential validation vs. parallel generation and voting
- Specialization: Clear role separation vs. diverse but similar agents
- Feedback: Explicit improvement cycles vs. aggregation strategies
Applications & Use Cases
High-Stakes Content Generation
- Legal Documents: Contract review and compliance checking
- Medical Reports: Clinical documentation with accuracy validation
- Financial Analysis: Investment reports with fact-checking
Creative Content with Standards
- Technical Writing: Documentation with accuracy and clarity validation
- Marketing Copy: Brand compliance and message consistency checking
- Academic Writing: Citation verification and argument structure evaluation
Code Generation & Review
- Software Development: Automated code review and bug detection
- Configuration Management: Infrastructure code validation
- Security Auditing: Vulnerability detection in generated code
Best Practices & Implementation Guidelines
Evaluator Design Principles
- Specific Criteria: Define clear, measurable evaluation standards
- Domain Expertise: Equip evaluators with relevant specialized knowledge
- Bias Awareness: Test for and mitigate systematic evaluation biases
- Feedback Quality: Ensure rejections include actionable improvement guidance
System Design Considerations
- Iteration Limits: Set maximum revision cycles to prevent infinite loops
- Quality Thresholds: Define minimum acceptance criteria
- Cost Management: Balance quality improvement against computational expense
- Fallback Mechanisms: Handle cases where convergence is not achieved
Socratic Questions for Self-Assessment
- Quality vs. Efficiency Trade-offs: How does the evaluator-optimizer pattern exemplify the fundamental tension between quality assurance and system efficiency, and under what circumstances would you prioritize one over the other in a production AI system?
- Evaluation Bias and Meta-Validation: If the evaluator agent can have biases or make errors in judgment, how might we validate the validators themselves, and what are the implications of creating hierarchical evaluation systems? Does this lead to an infinite regress problem?
- Human Collaboration Analogies: The pattern mirrors human collaborative processes like peer review and editorial feedback. How do the limitations and failure modes of human collaborative validation translate to AI systems, and what unique challenges emerge in the automated context?
- Convergence and Optimization: In what scenarios might an evaluator-optimizer system fail to converge on an acceptable solution, and how do these failure modes relate to broader questions about AI system alignment and the definition of "optimal" outputs?
- Scalability and Democratization: As this pattern increases computational costs significantly, what are the implications for AI system accessibility and the potential for creating "quality gaps" between resource-rich and resource-poor applications? How might this affect the democratization of AI technology?
Advanced Considerations
Multi-Evaluator Systems
- Ensemble Evaluation: Using multiple evaluators with different perspectives
- Hierarchical Review: Staged evaluation with increasing sophistication
- Specialized Validators: Domain-specific evaluators for different aspects
Dynamic Feedback Systems
- Adaptive Criteria: Evaluation standards that evolve based on task complexity
- Learning Evaluators: Validators that improve their assessment capabilities over time
- Context-Sensitive Validation: Adjusting evaluation approaches based on use case
Integration with Other Patterns
- Orchestrator-Worker-Evaluator: Combining orchestration with validation
- Pipeline with Quality Gates: Integrating evaluation into sequential workflows
- Multi-Agent Validation Networks: Complex validation topologies with multiple feedback paths
Study Resources & Further Reading
Foundational Papers
- Adversarial training methodologies and GAN architectures
- Reinforcement learning from human feedback (RLHF) research
- Multi-agent system coordination and validation studies
Industry Documentation
- Anthropic's AI system design pattern documentation
- OpenAI's content moderation and safety research
- Google's AI quality assurance frameworks
Related Academic Work
- Software engineering quality assurance methodologies
- Peer review and collaborative validation systems research
- Automated testing and continuous integration practices
